前回の更新はこちら。 rfコマンドのv1.17.0をリリースした。リリースしたのは1月の末なのだが、私が新型コロナウィルスに罹患してダウンしていたのでブログの更新が遅れた…。健康第一
🏕 Features
- Remove BufferedIO due to performance issues, introduce new Reader class by @buty4649 in https://github.com/buty4649/rf/pull/153
- Always use optimization flags by @buty4649 in https://github.com/buty4649/rf/pull/154
- Add grep/grep_v to instance method by @buty4649 in https://github.com/buty4649/rf/pull/155
- Remove strip option when host build by @buty4649 in https://github.com/buty4649/rf/pull/156
- Change non-existent method behavior to NoMethodError for clarity by @buty4649 in https://github.com/buty4649/rf/pull/157
- Allow infinite array size(MRB_ARY_LENGTH_MAX=0) by @buty4649 in https://github.com/buty4649/rf/pull/158
高速化 5.2秒 -> 1.36秒
v1.15.0に引き続き更に高速化した。 v1.15.0のときは1MB、104334行のファイルのgrepに5.2秒かかっていたが、v1.17.0では1.36秒になった。73%ほど速くなった。
$ rf --version rf 1.17.0 (mruby 3.2.0 f41593f) $ time rf -q -g hello /usr/share/dict/american-english ________________________________________________________ Executed in 1.36 secs fish external usr time 831.87 millis 194.00 micros 831.67 millis sys time 402.25 millis 122.00 micros 402.13 millis
遅くなっていた原因は、rfでは入力データの読み込みにはFile(IO)クラスではなくBufferdIOという独自のクラスを使っていた。 このクラスは、バッファをもたせたFile(IO)クラスで、入力データから先にバッファのサイズ分だけ読み出しておき、逐次そのバッファからデータを読み出すという処理にしていた。 このような処理にしている理由は、バイナリファイルの判定を行うためなのと、微々たるものだろうがIOの最適化である。
BufferdIOからデータを読み出す際に、String#slice!を呼び出しているのだがこれがボトルネックになっていた。 このボトルネックはperf record/perf reportコマンドを使って見つけ出した。 以下は実際にperf record/perf reportコマンドでrf v1.15.0の処理を分析した画像である。
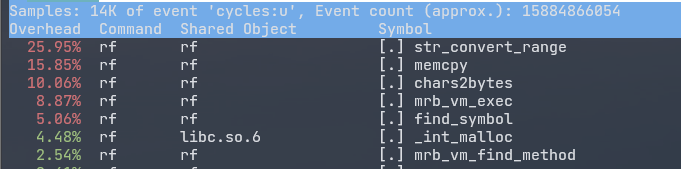
str_convert_rangeという関数にほとんどの処理時間がさかれているのがわかる。 このstr_convert_ragetはString#slice!から呼び出されているのでこれが被疑だということがわかった。
解決策としてシンプルにBufferdIOをやめた。 複雑なことはせず改行コードまでを読み出し、そしてデータにバイナリが含まれていないかをチェックするという処理にした。 これにより、若干grepや今までの挙動と変わってしまうのだが些細な問題であろう。
ちなみに余談だが、rfにおいてこのFile(IO)を抽象化したクラスの作り直しは3度目になる。 もしかしたら、やっぱりバッファを持たせたほうがよい!と判断して作り直すかもしれない。 そうなったら次はC言語で書くことになりそうかな。
Enumerator#grep_vを呼び出せるようにした
元々mrubyにはないメソッドなので機能追加のPRをした。 https://github.com/mruby/mruby/pull/6148
特に問題なくマージしてもらったので、この変更を反映したmrubyを使うように変更した。
作成できるArrayのサイズの上限をなくした(MRB_ARY_LENGTH_MAX=0)
mrubyでは作成できるとArrayのサイズ上限が存在する。 これはおそらく組み込み環境のようにメモリサイズが限られた環境を想定した措置だと思う。 しかしながら、rfにおいてはそういったことを気にする必要がなく、必要があれば必要な分だけArrayを作りたいので上限をなくした。